Деревья классификации и регрессии
- введение
- Вопросы классификации и регрессии
- Деревья классификации и регрессии ( C & RT - Деревья классификации и регрессии)
- Деревья классификации
- Деревья регрессии
- Преимущества метода деревьев классификации и регрессии ( C & RT )
- Общие вычислительные проблемы и уникальные особенности C & RT
- Избегайте переоснащения: тримминг, перекрестная проверка, V-перекрестная проверка
- Просмотр больших деревьев: уникальный инструмент для управления аналитикой
- Анализ систем типа ANCOVA
- Определение критериев оценки достоверности прогноза
- Выберите место
- Выбор конца приключений
- Обрезка и выбор дерева нужного размера
- Оценка точности в классификации
& copy Copyright StatSoft, Inc., 1984-2011
Поиск в справочнике по интернет-статистике
Деревья классификации и регрессии (C & RT)Введение в деревья классификации и регрессии - Основные идеи
введение
Модели деревьев классификации и регрессии (C & RT ) позволяют как создавать модели, которые легко решить проблемы регрессии (где переменная зависимость это черта чисел), а также классификация (зависимость качественных переменных). Классический алгоритм C & RT был распространен Бриманом и другими (Брейман, Фридман, Олшен и Стоун, 1984, см. Также Рипли, 1996). Общее введение в деревья классификации, в частности в алгоритм QUEST (Быстрые, непредвзятые, эффективные статистические деревья) также был представлен в теме Свойства деревьев классификации и следующее объяснение повторяет то же самое в несколько ином контексте. Еще один алгоритм построения деревьев CHAID (Автоматический детектор взаимодействия хи-квадрат, см. Kass 1980).
Вопросы классификации и регрессии
Существует множество алгоритмов, целью которых является прогнозирование значений непрерывных или категориальных переменных на основе набора прогнозирующих непрерывных переменных или эффектов категориальных факторов. Например, в GLM (General Line Models) и GRM (общие регрессионные модели) Мы можем определить линейную комбинацию (план) непрерывных предикторов и факторов категориального фактора (например, с взаимодействиями второго и третьего порядка) для прогнозирования непрерывной зависимой переменной. GDA (Общие модели дискриминантного анализа) мы определяем такие планы для прогнозирования категориальной переменной, решая задачу классификации.
Проблемы регрессии. У нас есть регрессии туда, где мы хотим узнать значение непрерывной переменной, основываясь на знании значения одной или нескольких переменных-предикторов и, альтернативно, переменных категорический , Например, нас интересует цена дома (переменная цена дочерняя компания ) мы знаем разные сиги предсказатели (как, например, поверхность квартиры), а также категориальные предикторы (такие как архитектурный стиль, район города или почтовый индекс - переменные к числовым, и все же, на самом деле, довольно категоричные). Используя простое предсказание цены дома множественная регрессия или общая линейная модель ( GLM ) Мы ищем уравнение верёвки, для которого вычисляем интересующие нас цены. Существует множество различных аналитических процедур для сопоставления линейных данных моделей ( GLM , GRM , регрессия ), нелинейные модели (например, Поднятые линейные и нелинейные модели (GLZ) , Допустимые аддитивные модели (GAM) и т. д.), а также нелинейные модели, полностью определяемые пользователем (см. Нелинейная оценка ), где вы можете ввести любое уравнение, содержащее параметры, значения которых будут найдены программой.CHAID также выполняет регрессионный анализ, результаты которого аналогичны результатам, полученным в C & RT . Отметим, что эти нейронные сети могут быть использованы для регрессии. Вопросы классификации. Классификация появляется там, где у нас есть категориальная переменная Zalen какое значение (т. е. случай принадлежит классу, группе) мы хотим узнать на основе знания значения одной или нескольких переменных-предикторов и, необязательно, переменных категорический , Например, нас интересует прогнозирование того, получит ли студент диплом, подписку подписчика или нет, и т. Д. Это примеры простой двоичной классификации, где категориальная переменная принимает только два значения. Однако нас может заинтересовать, кто из производителей автомобилей выберет клиента, или какое повреждение наиболее вероятно будет иметь место при данном типе двигателя. Здесь у нас есть много категорий или классов в категориальной переменной. Существует много методов анализа проблем классификации и предсказаний классов, как на основе простых переменных-предикторов (например, двух- и полиномиальных логит-моделей в GLZ ), категориальные предикторы (например, логарифмический анализ группирование таблиц) или использование переменных обоих типов одновременно (например, в планах ANCOVA, GLZ или GDA ). Общие модели CHAID также анализируют проблемы классификации, давая результаты такого же типа, как в C & RT. Отметим, что эти нейронные сети могут использоваться для классификации.
Деревья классификации и регрессии ( C & RT - Деревья классификации и регрессии)
Прежде всего, цель анализа с использованием алгоритма построения дерева состоит в том, чтобы найти набор условий логического деления, если таковые имеются, которые приводят к однозначной классификации объектов.
Деревья классификации
Давайте рассмотрим широко используемый пример классификации ириса (цветки косаки; Фишер 1936; см. Концепцию анализ дискриминантной функции и описание метода Анализ дискриминационной функции (GDA) ). Файл данных Irisdat содержит длины и ширины чашек и колб трех сортов ириса (Setosa, Versicol и Virginic). Цель анализа состоит в том, чтобы найти способ присвоения цветка одной из трех разновидностей на основе четырех измеренных его различных размеров. В анализе дискриминантной функции найдено несколько комбинаций линейных переменных-предикторов (здесь: дуго), позволяющих рассчитать вероятность принадлежности к классам, что, в свою очередь, позволяет выбрать наиболее вероятные классы для данного объекта. В отличие от этого, дерево классификации представляет собой набор логических условий (вместо линейного уравнения), которые позволяют классифицировать объект:
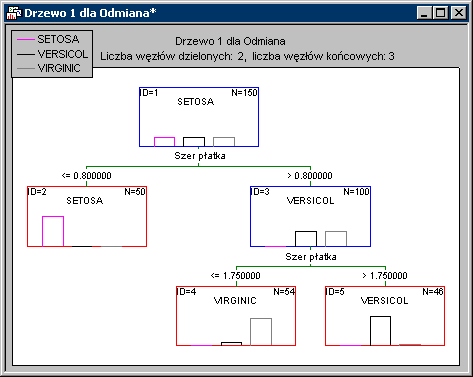
Интерпретация дерева прямая: если широкая полоса меньше или равна 0,8, то цветок классифицируется как Setosa; если, с другой стороны, широкая полоса больше 0,8, и в то же время она меньше или равна 1,75, то цветок, вероятно, является виргинским сортом; в противном случае это Versicol.
Деревья регрессии
Общий принцип получения предсказаний, основанный на нескольких простых логических условиях, может быть применен к проблемам регрессии. Давайте обратимся к примеру на основе данных из файла « Бедность» , содержащего результаты списков населения за 1960 и 1970 годы из случайно выбранных 30 округов. Задача исследования (в данном случае) состоит в том, чтобы найти причины бедности, то есть переменные, которые лучше всего предсказывают процент семей ниже порога бедности в округах. Текущий анализ этих данных с использованием деревьев регрессии определяется наилучшим деревом, из которого следует следующее:
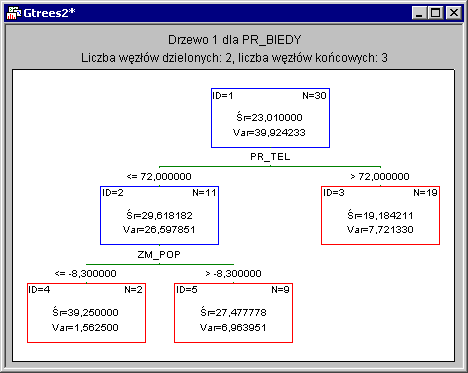
Как и в предыдущем случае, здесь интерпретация результата довольно прямая: в округах с процентным соотношением домохозяйств с номером телефона, превышающим 72%, процент бедности обычно ниже. Самый высокий уровень бедности отмечается в округах, где насчитывается менее 72% телефонов, а численность населения ниже -8,3 (люди быстро падают). Это очевидный результат, который легко представить: богатый район, где почти у каждого есть телефон, а у бедного - телефон, который не работает.
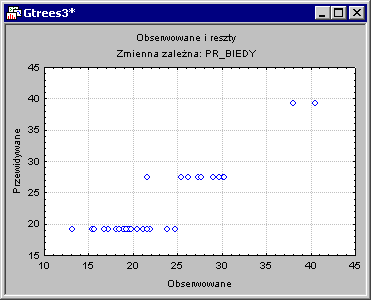
Достаточно взглянуть на диаграмму рассеяния значений, предсказанных наблюдаемыми, чтобы оценить, как модель разделяет две последние группы округов.
Преимущества метода деревьев классификации и регрессии ( C & RT )
Как указывалось ранее, существует множество методов анализа проблем классификации и регрессии, которые может использовать аналитик. Деревья классификации, если только «действуют» и дают хорошие прогнозы на основе нескольких условий, имеют много преимуществ по сравнению с другими методами.
Простота результатов. В большинстве случаев интерпретация результатов в виде дерева очень проста. Эта простота полезна не только потому, что новые случаи быстро классифицируются (будет легче проверить несколько логических условий, чем вычислять в качестве статистики классификации для каждой возможной группы или прогнозируемого значения на основе значения предикторов в модели, использующей сложные нелинейные уравнения), но также из-за гораздо более простых «модель», объясняющая, почему наблюдения классифицируются или прогнозируются таким образом, а не иначе (например, при анализе бизнес-задач будет легче представить несколько условий, если, чем, чем какие сложные уравнения).
Методы дерева классификации являются непараметрическими и нелинейными. Результаты, использующие методы деревьев классификации и регрессии, могут быть получены в виде нескольких (обычно несколько) логических условий типа if-it (с высоты дерева). Следовательно, нет первоначального предположения о характере взаимосвязи между предикторами и переменной зависимости - является ли она линейной или моделирует ли эта связь конкретную функцию вики [см. например. Поднятые линейные и нелинейные модели (GLZ) ] или даже однообразно ли это. Например, некоторые интересные количественные переменные могут положительно коррелировать с переменной Dochd , если она не превышает определенный размер, но отрицательно, когда она велика (в дереве она может быть настолько немонитной, в форме отношения к переменной Dochd). Методы дерева классификации хороши для задачи интеллектуальный анализ данных где априорные знания часто очень малы, и нет разумных теорий или оценок, с какими переменными связаны и каким образом. В этом виде анализа методы деревьев классификации могут обнаруживать связи между несколькими переменными, которые не будут обнаружены другими аналитическими методами.
Общие вычислительные проблемы и уникальные особенности C & RT
Детали относительно лица, которые в состоянии определить лучшие условия для разделения и создания простых и информативных деревьев, довольно продвинуты. В Breiman et al. (1984) описывает алгоритм CART® и общую теорию создания деревьев классификации и регрессии. Отличное объяснение методов деревьев классификации и регрессии наряду с другими методами распознавания образов и нейронными сетями представлено в Ripley (1996).
Избегайте переоснащения: тримминг, перекрестная проверка, V-перекрестная проверка
Очень важно при использовании деревьев классификации и регрессии для «реальных» данных, в которых присутствует много случайных шумов, принять решение, в какой момент прервать процесс приема. Например, если данные, которые у нас есть, содержат 10 случаев, вы можете создать 9 приключений ( если-то условия), которые будут выполнять идеальный прогноз для каждого из этих случаев. В общем, если мы будем восхищаться, мы сможем «предсказать» (было бы лучше «воспроизвести») исходные данные (те, которые используются для обозначения приключений). Конечно, не совсем ясно, будет ли такая сложная модель (со многими делениями) работать хорошо для попытки, состоящей из новых наблюдений, скорее всего, нет.
Эта общая проблема обсуждается в литературе по деревьям классификации, методам регрессии и нейронным сетям и называется «переоснащением» или «переоснащением». Если алгоритм создания дерева не останавливается, вся информация будет «извлечена» из данных, включая те, которые не могут быть получены из всего населения с заданным набором предикторов, например, случайной величиной или шумом. Общий подход к этой проблеме состоит в том, чтобы нарушить процесс создания новых каблуков со сбоями, когда последующие подразделения дают небольшое увеличение прогностической достоверности. Например, если мы можем точно предсказать 90% всех случаев, используя 10 дифференцировок, и 90,1% для помощи 11, то нет смысла добавлять одиннадцатое деление в модель. Остановить процесс разведки (построения дерева) можно на основе разных критериев.
Когда алгоритм построения дерева уже останавливается, значение всегда будет оцениваться как прогноз с использованием созданного в настоящее время дерева, применяя его к новым наблюдениям, которые не использовались для построения модели. Этот метод может использоваться для «обрезки» дерева, то есть дерева, которое проще созданного, но имеет предсказательную точность, аналогичную «новым» наблюдениям.
Перекрестная проверка. Один из подходов состоит в том, чтобы использовать дерево, созданное на основе одного набора наблюдений (пробный период), другому независимому набору наблюдений (тестовый образец). Если большинство или все деления, определенные анализом тестовой выборки, основаны на «случайном шуме», то прогноз в тестовой выборке будет очень плохим. Тогда можно сделать вывод, что выбранное дерево является сабом (оно бесполезно) и «правильного размера» не существует. V-кратный тест крест - накрест. Продолжая эту линию рассуждений (см. Выше перекрестную проверку), вы можете повторить один и тот же анализ несколько раз для разных случайных выборок, выбранных из данных, для каждого размера дерева и применить его к наблюдениям из выборочных выборок, выбранных случайным образом. Затем выберите (примите в качестве модели результата) дерево, которое дает наилучшую среднюю точность прогнозирования. Обычно это не дерево с большим количеством гепатита, то есть самое сложное. Этот метод сокращения дерева и выбора меньшего дерева из всего диапазона деревьев может быть очень сильным и чрезвычайно полезным для небольших наборов данных. Этот шаг имеет решающее значение при создании полезных (предсказуемых) моделей деревьев. Поскольку это может быть сложным в вычислительном отношении, оно отсутствует во многих пакетах для деревьев классификации и регрессии.Просмотр больших деревьев: уникальный инструмент для управления аналитикой
Другая проблема, связанная с использованием деревьев классификации и регрессии, - это возможность создания очень больших деревьев. На практике, если данные сложны и, например, содержат много разных категорий (в задачах классификации) и много предикторов, модель можно создать в виде очень большого дерева. В настоящее время это не вычислительная проблема, а скорее проблема с представлением этого дерева способом, удобным для аналитика и «клиента» анализа.
Анализ систем типа ANCOVA
Классические (Breiman et al., 1984) алгоритмы деревьев классификации и регрессии поддерживают количественные и качественные переменные. На практике, однако, нередки случаи, когда такие переменные включаются в анализ, в механизмы прогнозирования, такие как анализ дисперсии / ковариации с корневыми факторами или взаимодействия для факторов качества и количественных предикторов. Этот метод анализа ANCOVA является совершенно новым. Сразу видно, что использование кодированных схем позволяет использовать эти мощные методы классификации и регрессии для анализа данных из экспериментальных планов (см., Например, объяснение методов планирования, опыт контроля качества в части Планирование и анализ опыта в промышленной статистике).
Вычислительные детали
При расчете и создании деревьев классификации и регрессии можно сделать четыре основных шага:
- Определение критериев оценки достоверности прогноза
- Выберите место
- Определение того, в какой момент остановится процесс генерации похвал
- Выберите дерево «правильного размера».
Перечисленные этапы очень похожи на описанные в описании. Деревья классификации , См. в частности методы расчета и Брейман и др., 1984
Определение критериев оценки достоверности прогноза
Целью применения классификационных и регрессионных (C & RT) алгоритмов классификации обычно является получение модели с наилучшей прогностической достоверностью. При желании вы можете определить наиболее точный прогноз как t, который имеет самые низкие затраты. Концепция стоимости была создана как осознание большинства прогнозирующих ситуаций идеи о том, что модель с самой низкой оценкой является лучшим предиктором. В большинстве приложений показатель стоимости - это отношение количества дел, классифицированных ко всем, или дисперсии. В этом контексте прогноз будет наилучшим, если он имеет наименьшую ошибочную оценку или наименьшую дисперсию. Необходимость управлять минимизацией затрат, а не просто ошибкой классификации, обусловлена тем фактом, что некоторые ошибки классификации могут иметь более катастрофические последствия, чем другие.
Вероятность априори. В случае качественной зависимой переменной (проблемы классификации) минимизация затрат означает наименьшую долю ошибочной классификации случаев, тогда как априорные вероятности пропорциональны размеру классов, а ошибочные затраты равны во всех классах.
Вероятности, которые априори используются при минимизации затрат, могут оказать большое влияние на классификацию случаев (объектов). Это означает, что вы должны заранее позаботиться о правильном использовании вероятностей. Если разные вероятности классов не имеют отношения к анализу или известно, что в каждом классе имеется более или менее одинаковое количество случаев, мы априори используем одинаковые вероятности. Если число классов отражает вероятности классов, что является, например, правдой в случае случайно выбранной вероятностной выборки, следует использовать оценки вероятности на основе пропорций в выборке. В последнем случае, когда мы знаем, каковы вероятности (например, на основе предыдущих опросов), мы априори используем фиксированные вероятности. Дело в том, что величина априорных вероятностей, присвоенных классам, может использоваться для «исправления» неправильных классификаций для каждого класса. В случае деревьев регрессии нет необходимости предоставлять эти вероятности.
Издержки неправильной классификации. В определенных ситуациях дается более точная классификация некоторых классов зависимой переменной, чем другие (по причинам, не зависящим от количества классов). Если в качестве критерия прогнозирования мы выберем неправильные затраты на классификацию, то минимизация затрат сведет к минимуму пропорции классифицированных случаев, в результате чего вероятности априори будут пропорциональны размеру классов, а ошибки классификации в каждом классе будут одинаковыми.
Шкалы шкафов. В деревьях классификации и регрессии веса дел рассматриваются как коэффициенты (множители). Например, коэффициенты погрешности классификации, полученные в результате анализа данных, агрегированных с данными весами наблюдений, будут такими, которые получены в результате анализа одних и тех же данных, в которых каждый случай повторяется столько раз, сколько весов.
Однако следует отметить, что использование весовых коэффициентов в агрегированных данных в случае проблем классификации связано с минимизацией затрат. Вместо весов наблюдений для агрегированных данных вы можете дать соответствующие априорные вероятности и / или затраты на неправильные оценки и получить те же результаты, вычисления выполняются быстрее, если вы избегаете обработки многих случаев с одним и тем же значением всех переменных. Слухи о том, что набор данных содержит два класса с одинаковым числом случаев, где первому классу присваивается вес случая 2, а во второй - 3. Если мы задаем априорные вероятности как 0,4 и 0,6 соответственно, и затраты на ошибочные классификации будут одинаковыми, и мы будем анализировать данные без весов случаев, мы получим тот же результат, то есть тот же коэффициент ошибок, что и в случае анализа агрегированных данных с весами случаев, вероятностями, оцененными на основе размеров классов и предполагающими различные категориальные затраты. Те же результаты будут получены с учетом тех же вероятностей априори и предоставлением стоимости неправильной классификации случаев класса 1 как класса 2 при росте 2/3 стоимости классификации случаев класса 2 как класса 1 и анализа данных без весов случаев.
Выберите место
Вторым шагом в построении деревьев классификации и регрессии является выбор предикторов, которые используются для создания другого деления и прогнозирования принадлежности случая к классу зависимых переменных или для прогнозирования количественного значения зависимой переменной. В частности, программа в каждой лунке ищет разделение, которое дает наибольшее улучшение в прогнозной достоверности. Мы обычно измеряем его как меру примеси, которая указывает на относительную однородность (обратное загрязнение) случаев в конечной нити. Если дела в попытках имеют одинаковые значения, загрязнение минимально, а однородность максимальна, и идеальный прогноз (сумма случаев, использованных при расчете модели, вопрос точного прогноза для новых случаев является вопросом ...).
В задачах классификации C & RT можно выбрать различные меры неоднородности: индекс Джини, хи-квадрат или G-квадрат. Индекс загрязнения Джини является мерой, наиболее часто используемой в задачах типа классификации. В качестве меры загрязнения он принимает значение, равное нулю, только когда в данном случае имеется только один класс. Если априорные вероятности оцениваются на основе количества классов и неправильной стоимости классификации, то мера неоднородности Джини по константе рассчитывается как сумма после всех пар классов акций этих классов в ряду - максимум достигается, если число классов в ранге Мера хи-квадрат аналогична стандартной статистике хи-квадрат, рассчитанной для ожидаемых и наблюдаемых чисел (с априорными вероятностями, учитывающими затраты на ошибочную классификацию), тогда как коэффициент Джини равен 0. мера G-квадрата подобна хи-квадрат наибольшей надежности (рассчитывается, например, в модуле логарифмический анализ ). В задачах регрессии программа автоматически использует критерий наименьших квадратов (аналогично методу наименьших квадратов, используемому в вычислениях регрессии). См. Расчеты, формулы ,
Выбор конца приключений
Как было указано в разделе « Основные идеи» , в принципе, перерывы могут продолжаться до тех пор, пока не будет получена идеальная классификация. Однако это не имеет особого смысла, когда полученная древовидная структура будет очень насыщенной и такой же «точной», как и исходные данные (со многими пробелами, при которых часто будут наблюдаться отдельные наблюдения), такая модель, вероятно, не даст хороших предсказаний новых наблюдений. Вам нужна разумная остановка регуа. В C & RT есть два варианта остановки - минимальное n и фракция объектов .
Минимальное количество Один из способов управления процессом отсрочки заключается в том, что деления выполняются до тех пор, пока все заключительные повороты не станут однородными или не содержат не более определенного минимального числа случаев. В C & RT это означает выбор минимальной опции, чем указание указанного минимального количества случаев в качестве критерия для прекращения процесса предоставления. Этот параметр можно использовать, если в качестве остановки для анализа задан останов для сортировки, для сортировки - «Обрезать», для отклонения - «Обрезать для отклонения».
Фракция объекта Другим способом управления процессом согласования является проведение согласования до тех пор, пока все конечные очереди не станут однородными или не содержат не более определенной доли классов (в случае задач типа классификации и доли случаев в задачах регрессии). Эта опция может быть использована, если, как правило, мы используем прямой тип остановки ФАКТ , В C & RT минимальная доля может упоминаться как доля объекта. В задачах классификации: если априорные вероятности, использованные в анализе, равны, а размеры классов равны, процесс согласования будет остановлен, когда при завершении более чем одного класса буреломов не будет больше, чем заданная доля объектов. Если априорные вероятности не равны, процесс вынесения решения остановится в тот момент, когда в окончательных выводах, содержащих наблюдения из более чем одного класса, будет не более данной доли случаев. См. подробности в Loh and Vanichestakul, 1988.
Обрезка и выбор дерева нужного размера
Подходящий размер дерева в анализе с использованием деревьев классификации и регрессии является серьезной проблемой, слишком большое дерево может быть трудно интерпретировать. Есть несколько общих правил того, каким должно быть дерево «большого размера». Он должен быть достаточно информирован, чтобы отражать известные факты, и в то же время он должен быть максимально простым. Он должен использовать информацию, которая дает прогнозную точность, и игнорирует те, которые не дают такого увеличения. Это должно, если возможно, дать лучшее понимание описанного явления. Опции, доступные в C & RT, позволяют использовать две стратегии (по отдельности или вместе), чтобы выбрать дерево «правильного размера» из набора всех возможных деревьев. Одна стратегия состоит в том, чтобы создать дерево так, чтобы оно достигло нужного размера, в то время как пользователь определяет размер диагностической информации из предыдущих анализов и даже интуиции, основываясь на предыдущих исследованиях. Вторая стратегия заключается в использовании хорошо документированных процедур, данных Брейманом и другими (1984), для выбора дерева «правильного размера». Процедуры не надежны, как подчеркивают авторы, но не полагаются на субъективные оценки.
Прямая фактическая остановка. В этом случае проверяются все возможные разбивки для каждой переменной прогнозирования, чтобы найти деление, с которым происходит наибольшее улучшение качества соответствия (или наибольшее уменьшение несоответствия). Что определяет районы возможных приключений в данной деревне? Для номинальных переменных предиктора zk уровней в данном узле мы имеем 2 (k -1) - 1 возможных контрастов между двумя наборами уровней этого предиктора. Для массивов заказов с различными уровнями, встречающимися в данном узле, у нас есть k -1 центральных точек между различными уровнями. Таким образом, можно видеть, что число возможных примесей, которые должны быть проанализированы, может быть очень большим, если у нас много предикторов со многими уровнями, которые необходимо анализировать во многих отношениях. Первый способ - определить размер дерева пользователем. Этот метод будет использоваться, если вы решите напрямую остановить тип ФАКТ в качестве правила остановки и задайте долю объекта , которая позволит дереву расти до указанного размера. У C & RT есть много опций, которые предоставляют диагностическую информацию, позволяющую разумно судить о выбранном дереве. В частности, существует три варианта перекрестной проверки: тестовый тест, v и минимальная стоимость.
Кросс-тест в тестовом прогоне. Первый тип перекрестной проверки (и наиболее часто используемый) - это тест в тестовом прогоне. В этом случае дерево создается на основе обучающего испытания, и его точность оценивается на основе прогноза в тестовом образце. Стоимость в тестовом образце больше, чем в случае, следует понимать как тест с низкой перекрестной оценкой. В этом случае дерево другого размера может быть лучше при перекрестной проверке. Вы можете создать тест и праздник, взяв два независимых набора данных или, если у вас большая выборка, путем случайного выбора случаев (например, одна треть, половина) и используя его в качестве тестовой выборки.
В модуле C & RT перекрестная проверка в тестовом образце выполняется путем указания переменной, идентифицирующей тест (пиры и тесты).
V-кратный тест крест-накрест. Вторым типом перекрестной проверки, доступной в C & RT, является перекрестная проверка v-fold. Этот метод удобен, если нет попытки теста, а попытка участника слишком мала, чтобы отделить тест от него. Значение 'v', данное пользователю для этого теста (по умолчанию 3), указывает число субприп, если возможно, случайных чисел, случайно созданных в результате попытки обучения. Дерево заданного размера вычисляется 'v' раз, каждый раз, когда к расчету берутся случаи, за исключением одной подвыборки, которая используется в качестве тестовой выборки. Таким образом, каждый из субстратов используется (v - 1) раз в образце и только один раз как тестовый прогон. Стоимость SK (перекрестная проверка) рассчитывается как средняя стоимость тестов 'v', которая является оценочной стоимостью для SK.
Подравнивание в соответствии с минимальной сложностью, измеряемой за счет перекрестной проверки. Модуль C & RT использует обрезку в соответствии с минимальной стоимостью и сложностью перекрестной проверки, если вы выбираете опцию Обрезать по классификации, как правило . Если вы выберете Обрезать при наклоне, обрезка будет выполняться в соответствии с минимальной сложностью, измеряемой отклонением. Эти два варианта отличаются только способом измерения ошибки прогнозирования. Опция Trim для классификации использует среднюю частоту ошибок для вероятности априори и различных оценок ошибок, а Crop для отклонения использует меры, основанные на принципах максимальной вероятности, называемой отклонением (см. Ripley, 1996). Подробно об используемых алгоритмах из модуля C & RT, реализованных в тримминге, в соответствии с минимальной сложностью, измеренной за счет перекрестной проверки, см. Введение в деревья классификации. Основные понятия и Методы расчета в честь Деревья классификации ,
Последовательность деревьев, полученная с помощью этого алгоритма, имеет несколько интересных свойств. Деревья в последовательности являются вложенными, так как они последовательно сокращаются и содержат все ветви в следующей меньшей последовательности деревьев. Первоначально, при переходе от одного к следующему, меньшему дереву, многие часто срезаются, но при приближении к корню сокращается меньше каблуков. Последовательность самых больших деревьев также оптимально сокращается, поскольку для каждого размера дерева в последовательности нет другого дерева того же размера, которое стоило бы с меньшими затратами. Обоснование и объяснение этих способностей приведены в: Breiman et al. (1984).
Выберите дерево после обрезки. Обрезка, описанная выше, дает оптимально усеченную последовательность деревьев. Следующим шагом является использование соответствующего критерия для выбора дерева «правильного размера» из такой серии оптимальных деревьев. Естественным критерием является стоимость СК (перекрестная проверка). Хотя нет ничего плохого в выборе дерева с минимальной стоимостью перекрестного допроса в качестве дерева правильного размера, часто бывает так, что у нас будет несколько деревьев с минимальными затратами на перекрестную проверку. Процедура автоматического выбора дерева может использовать предложение Бреймана. Брейман и др. (1984) предлагают выбрать дерево наименьшего размера (наименее положительно) в качестве дерева правильного размера, затраты на перекрестную проверку которого не сильно отличаются от минимальных затрат на перекрестную проверку. Предложите здесь правила одной стандартной ошибки, т. Е. В качестве дерева правильного размера выберите дерево наименьшего размера, затраты на перекрестную проверку которого не превышают минимальную стоимость перекрестной проверки плюс 1 или стандартную стоимость перекрестной проверки для дерева с минимальной стоимостью перекрестной проверки. В модуле C & RT вы можете ввести значение коэффициента для стандартного правила ошибки (кроме значения по умолчанию 1). Таким образом, указание значения 0.0 приводит к правильному размеру перекрестной проверки как к дереву правильного размера. Значения больше 1,0 приводят к выбору деревьев, намного меньших, чем дерево с наименьшей стоимостью перекрестной проверки. Особое преимущество процедуры автоматического выбора дерева состоит в том, что она помогает избежать чрезмерной корректировки (чрезмерной корректировки) или несоответствия данным.
Как видите, процедура выбора является «автоматическим» процессом. Сам алгоритм принимает все решения, ведущие к выбору дерева «правильного размера», он может быть вне выбора значений для стандартного правила ошибок. Независимо от способа создания и вырезания дерева, C & RT содержит параметры в окнах результатов или перекрестной проверки, которые позволяют выполнять перекрестную проверку для каждого дерева из полученной последовательности деревьев. Эта команда позволяет оценить, насколько хорошо каждое из деревьев «ведет себя» при многократной перекрестной проверке различных случайно выбранных данных.
Расчеты, формулы
В деревьях классификации и регрессии точность моделей классификации и регрессии оценивается на основе различных форм. При классификации (классифицированная переменная зависимости) количество правильных классификаций точно измеряется, а при регрессии (зависимость переменной Сига) оно точно рассчитывается как среднее или квадратное предсказание.
В дополнение к показателям точности в задачах классификации вычисляются следующие показатели нерегулярности узла : измерения Джини, экспонированный критерий хи-квадрат и критерий G-квадрата. Мера хи-квадрат основана на стандартном хи-квадрат, рассчитанном для ожидаемых и наблюдаемых классификаций (с учетом стоимости неправильных классификаций). Мера G-квадрата основана на хи-квадрате самой высокой надежности (как в анализе Логлинейный ). Описанная в нем мера Джини относится к наиболее часто используемой классификации мер по удалению.
В случае регрессии для непрерывной зависимой переменной автоматически применяется мера, основанная на наименьшем отклонении наименьших квадратов (LSD).
Оценка точности в классификации
В классификациях (с классифицированной зависимой переменной) используются три оценки точности: повторное замещение, тестовый образец и V-кратная проверка. Определения приведены ниже.
Оценка по повторной замене. Это доля дел, классифицированных по классификационной модели на основе всех дел. Шаблон выглядит следующим образом: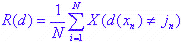
где X - функция индексов;
X = 1, если выражение 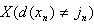 это реально
это реально
X = 0, если выражение это ложь
и d (x) - модель классификации.
Эта мера рассчитывается для того же набора данных, на основе которого была построена модель d.
Оценка основана на тестовом тесте. Все данные случаев делятся на две группы Z 1 и Z 2. Рейтинг точности классификации - это доля случаев в группе Z 2, классифицированных по модели, основанной на группе Z 1. Он рассчитывается следующим образом:
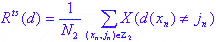
где N 2 - количество случаев в группе Z 2, которое не использовалось при построении модели.
Проверка V-креста. Все случаи данных делятся на v групп Z 1, Z 2, ..., Z vo одинакового числа, насколько это возможно. Рейтинг точности классификации - это доля случаев в группе Z, которые классифицированы моделью на основе случаев Z - Z против группы. Здесь применяется следующая формула:
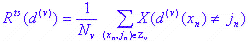
где 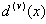 рассчитывается для Z-Z v.
рассчитывается для Z-Z v.
Оценка точности в регрессии
Проблемы регрессии (с непрерывной зависимой переменной) используют три оценки точности: повторное замещение, тестовый образец и V-кратное подтверждение. Определения приведены ниже.
Оценка по повторной замене. Ожидаемая квадратная ошибка рассчитывается здесь на основе прогноза зависимой переменной. Шаблон выглядит следующим образом:
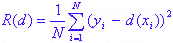
где попытка учащегося Z состоит из точек (xi, yi), i = 1,2, ..., N. Эта мера рассчитывается для того же набора данных, на основе которого была построена модель d.
Оценка основана на тестовом тесте. Все данные случаев делятся на две группы Z 1 и Z 2. Оценка точности рассчитывается по формуле ниже:
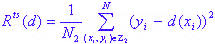
где N 2 - количество случаев в группе Z 2, которое не использовалось при построении модели.
Проверка V-креста. Все данные делятся на v групп Z 1, Z 2, ..., Z v как можно большего числа. Группа образцов Z - Z v используется для построения модели d. Оценка точности рассчитывается для выборочной группы Z v следующим образом:
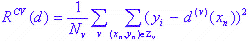
где 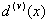 рассчитывается для Z-Z v.
рассчитывается для Z-Z v.
Оценка неоднородности: мера Джини
Мера несогласованности Джини часто используется в ситуациях, когда зависимость от переменной является категорированной переменной. Определение следующее:
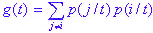
если неоправданная стоимость классификации или неравные вероятности не были определены априори , и
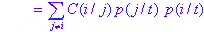
когда ошибочные затраты на классификацию или неравные вероятности даны априори .
В формулах суммирование продолжается после всех k категорий. С другой стороны, p (j / t) - это вероятность категории jw w t, а C (i / j) - это вероятность классификации категории j как i.
Следует отметить, что определение неравных вероятностей априори может повлиять на прогнозирование данного дерева классов.
Рейтинг непонятности: отклонение по методу наименьших квадратов (LSD)
Наименьшее отклонение квадратов часто используется для несущественных мер в ситуациях, когда зависимая переменная является переменной Чейза. Определение следующее:
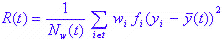
где N w (t) - вес числа случаев в t, w - значение переменной для случая i, fi - переменная частота, yi - значение переменной отклика, а y (t) - среднее значение, взвешенное в th.

& copy Copyright StatSoft, Inc., 1984-2011
STATISTICA является торговой маркой StatSoft, Inc.
Похожие
Определение доставки сомнительноПредприниматели должны пересмотреть действующие правила определения сроков доставки товаров получателям. Налоговые консультанты советуют, чтобы эти даты были одинаковыми для обеих сторон сделки. В противном случае возникнет проблема с налоговым обязательством. Доставка товаров или оказание услуг - это момент, когда возникает налоговое обязательство в налоге на товары и услуги (НДС). Это общее правило этого года. В следующем месяце впервые будет уплачен НДС по таким завершенным сделкам. Количественный и качественный анализ или методы оценки нашей кредитоспособности
Банк делает премию условной ипотека от кредитоспособности клиента, которая понимается как способность полностью погасить договорное обязательство плюс проценты в сроки , указанные в кредитном договоре . Таким образом, заемщик обязан предоставить банку необходимую информацию и документы для проведения банком оценки его кредитоспособности на основе внутренних процедур, действующих в банке. В случае, если ABC делает хорошие фотографии: обрезка
... деревья или открытые двери или окна. Эта обработка позволяет создать естественный край фотографии, придать ей глубину и привлечь внимание зрителя к внутренней части композиции. Приведенная Технический анализ: когда покупать акции?
Технический анализ против Фундаментальный анализ Часто говорят, что технический анализ и фундаментальный анализ не являются хорошими друзьями, и те, кто использует один, не используют другой. Это не совсем так. Технический анализ может стать хорошим дополнением для инвестора на фондовом рынке, который в основном руководствуется фундаментальным аспектом при покупке ценных бумаг. В фундаментальном анализе рассматриваются результаты Место работы и расходы на персонал
... ик, проживающий в городе X в трудовом договоре в качестве места работы, имеет два адреса: местный X и местный Y"> Вопрос: Работник, проживающий в городе X в трудовом договоре в качестве места работы, имеет два адреса: местный X и местный Y. Если в течение одного месяца работник будет работать только в городе X, а во втором месяце четыре дня в неделю в городе X и один день в неделю в деревне Y расходы на получение дохода должны меняться в соответствии Создание собственной системы управления документами в Office 365
К нам пришла ведущая глобальная строительная компания, нуждающаяся в новой платформе, которая позволила бы решить проблемы, с которыми они столкнулись в своей существующей системе управления документами. Их решение должно было позволить пользователям из всех географических местоположений в компании, а также внешним пользователям эффективно получать доступ к политикам, процедурам и стандартам для выполнения своих повседневных задач при одновременном соблюдении требований соответствия. Определение лидерства: есть ли идеальный профиль лидерства?
... rt-_-alert_date&utm_source=newsletter_daily_alert&utm_medium=email&utm_campaign=alert_dat> Эта статья в бизнес-обзоре Гарварда от Брэда Пауэра. Он утверждает, что лидерство на уровне генерального директора часто сосредоточено на людях, которые «любят работать в мире идей» и «не имеют конца теории, анализа, возможных вариантов будущего и сценариев« что если »». Он говорит, что ему не хватает черт личности, которые основаны на процессах и реализации - тех, Анализ данных в медицинских науках - StatSoft Polska
На 9-16.X.2000 компания StatSoft организовал семинары в Варшаве по применению статистики и анализа данных. Мы хотели бы поблагодарить всех участников семинаров этого года за их участие и положительное мнение о лекциях и презентациях. Мы поставили цель проведения семинаров с целью распространения знаний в области статистики и анализа Свечи накаливания
Политика в отношении файлов cookie Наш веб-сайт использует файлы cookie, чтобы обеспечить вам комфорт при просмотре нашего сайта и повысить качество контента. Мы также используем куки-файлы для того, чтобы, например, корректировать содержание показанной вам рекламы в соответствии с вашими интересами. Если вы продолжаете просматривать наш сайт без изменения настроек браузера, мы предполагаем, что вы согласны с использованием APX Technologies
... иза программного обеспечения, доступного на польском рынке, APX Technologie решила решить enova365. Проблемы для enova365 Из-за различных систем и рассредоточенной информации в APX Technologie, проблема была в первую очередь: отсутствие одной базы данных, невозможность эффективного управления данными, а также управление складом на производстве, ограниченный контроль над текущими проектами и, следовательно, сложная проверка рентабельность реализуемых проектов. Система Определение проекта: когда проект является проектом? > Agile-master.de
Термин проект сегодня очень широко используется, почти инфляционный. Иногда даже в шутку говорят о проектите. Чтобы избежать распространения проектов и использовать операционные ресурсы настолько экономно, насколько это возможно, часто требуются ориентированные на практику критерии принятия решений. Поэтому в этой статье я рассматриваю два вопроса: что такое проект? И когда имеет смысл создать проектную организацию? Статья состоит из нескольких разделов. Во-первых, давайте
Комментарии
Итак, какие вопросы вы должны задать себе, чтобы определить, используете ли вы инструмент таким образом, который наилучшим образом соответствует потребностям вашей команды?Итак, какие вопросы вы должны задать себе, чтобы определить, используете ли вы инструмент таким образом, который наилучшим образом соответствует потребностям вашей команды? В 1999 году Тиагараджан опубликовал одно из крупнейших исследований поведения фасилитатора с использованием метода, который объединяет науку с опытом. Этому предшествовало 10-летнее изучение этого предмета. Наблюдения Тиагараджана очень интересны: «Мы не нашли согласованного и общего поведения между фасилитаторами, Использует ли ваша организация устаревшие локальные технологии для управления вашей корпоративной документацией?
Использует ли ваша организация устаревшие локальные технологии для управления вашей корпоративной документацией? Связаться с контентом и кодом чтобы узнать, как мы можем помочь вам перейти в облако с Office 365. На какие вопросы отвечает руководство: Деятельность незарегистрированного практического руководства для начинающих?
На какие вопросы отвечает руководство: Деятельность незарегистрированного практического руководства для начинающих? Сегодня мы отвечаем на дальнейшие вопросы из списка. Чтобы прочитать ответы на вопросы, на которые мы уже ответили, просто нажмите на соответствующую ссылку. Из-за широкого спектра материалов, мы публикуем руководство в разделах, и, наконец, мы опубликуем его в формате PDF для загрузки в целом. Последующие части будут опубликованы в последующие дни. КАКИЕ ПРЕИМУЩЕСТВА ПРОВЕРЯТ ИСТОРИЮ КРИСТАЛЛА?
КАКИЕ ПРЕИМУЩЕСТВА ПРОВЕРЯТ ИСТОРИЮ КРИСТАЛЛА? Вы должны проверить свою кредитную историю по нескольким важным причинам: Подготовка к посещению банка Мониторинг данных Проверка оценки (скоринг) Защита от кражи личных данных Подтверждение достоверности и надежности Каждый может использовать свой «сертификат надежности» в различных ситуациях, требующих заключения договора или подтверждения их достоверности, Какие преимущества дает двойная камера и предоставляет вообще?
Какие преимущества дает двойная камера и предоставляет вообще? Мы решили проверить на практике. Прежде чем ответить на этот вопрос, нужно уточнить, что существует по меньшей мере 9 вариантов, как может использоваться двойная камера в смартфоне. технологическое разнообразие Вас интересует тема и есть дополнительные вопросы?
Вас интересует тема и есть дополнительные вопросы? Хотели бы вы получить ДЕМО версию? Или, может быть, вы заинтересованы в презентации наших решений? Свяжитесь с нами, используя форму ниже: Но достаточно ли свержения - или, по крайней мере, ослабления - мифа о богатых как кузнецах своей собственной судьбы, чтобы оправдать насильственное перераспределение в больших масштабах?
Но достаточно ли свержения - или, по крайней мере, ослабления - мифа о богатых как кузнецах своей собственной судьбы, чтобы оправдать насильственное перераспределение в больших масштабах? Трудно дать однозначный ответ. Одно можно сказать наверняка: влияние интеллекта на заработки является значительным, и по мере развития технологий оно будет расти, поэтому экономисты и специалисты по этике должны принимать это во внимание в своей работе. У вас есть дополнительные вопросы?
У вас есть дополнительные вопросы? заполнить контактная форма - мы свяжемся с вами или позвоним нашему консультанту по телефону 801 355 455 или +48 22 543 34 34. Финансирование ЭКО Кредит PV это: Закупка и установка новых солнечных установок на заводе (не относится к оборудованию, покупка которого финансировалась за счет займа при софинансировании от WFOŚiGW / NFOŚiGW). Размышляя о выборе того или иного решения, сразу возникают первые вопросы: как выбрать коллекционеров?
Размышляя о выборе того или иного решения, сразу возникают первые вопросы: как выбрать коллекционеров? Выгодно ли это в нашей стране? солнечные коллекторы отапливают дом? - В нашем климате самые высокие тепловыделения от солнечной энергии приходятся на период с весны до начала осени, когда мы не отапливаем свои дома. В течение этого времени коллекторы можно использовать для подогрева горячей воды, для подогрева бассейна. В свою очередь, в отопительный период коллекторы могут обогревать Джейк, есть ли преимущества использования многоступенчатого эжектора по сравнению с одноступенчатым эжектором?
Джейк, есть ли преимущества использования многоступенчатого эжектора по сравнению с одноступенчатым эжектором? Одноступенчатый эжектор рассчитан на высокий поток вакуума и высокий уровень вакуума. Многоступенчатый эжектор COAX® имеет комбинацию различных форсунок, обеспечивающих как высокую эффективность потока, так и высокий уровень вакуума. Эта конструкция также дает меньше энергии для аналогичной Каковы будут преимущества перевода средств на банковский счет НДС?
Каковы будут преимущества перевода средств на банковский счет НДС? Я подробно писал о преимуществах здесь , На данный момент, я просто хочу подчеркнуть, что преимуществами этого решения являются отсутствие солидарной ответственности, отсутствие дополнительных налоговых обязательств, снижение суммы налоговых обязательств и ускоренное возмещение НДС.
Что определяет районы возможных приключений в данной деревне?
Определение лидерства: есть ли идеальный профиль лидерства?
Поэтому в этой статье я рассматриваю два вопроса: что такое проект?
И когда имеет смысл создать проектную организацию?
Итак, какие вопросы вы должны задать себе, чтобы определить, используете ли вы инструмент таким образом, который наилучшим образом соответствует потребностям вашей команды?
Использует ли ваша организация устаревшие локальные технологии для управления вашей корпоративной документацией?
На какие вопросы отвечает руководство: Деятельность незарегистрированного практического руководства для начинающих?
КАКИЕ ПРЕИМУЩЕСТВА ПРОВЕРЯТ ИСТОРИЮ КРИСТАЛЛА?
КАКИЕ ПРЕИМУЩЕСТВА ПРОВЕРЯТ ИСТОРИЮ КРИСТАЛЛА?
Какие преимущества дает двойная камера и предоставляет вообще?